
Bygg en datamodell ni kan lita på
I vårt tidigare webinar fokuserade vi på vad Onboarder kan göra. I detta webinar tar vi nästa steg och visar hur ni gör det i praktiken i er organisation.
För många företag uppstår utmaningarna först när modellen möter verkligheten. Det som fungerar i teorin eller med ren testdata håller inte när datan är ofullständig, varierande eller rörig. Därför fokuserar vi i detta webinar på hur datamodellen ska utformas så att både ni och era leverantörerna förstår den och hur den testas med realistisk data – inklusive det som är ofullständigt eller rörigt – utan att bygga på önsketänkande.
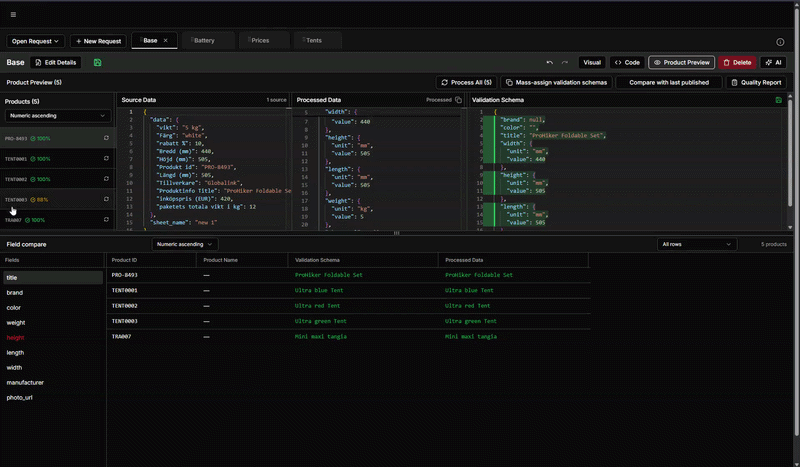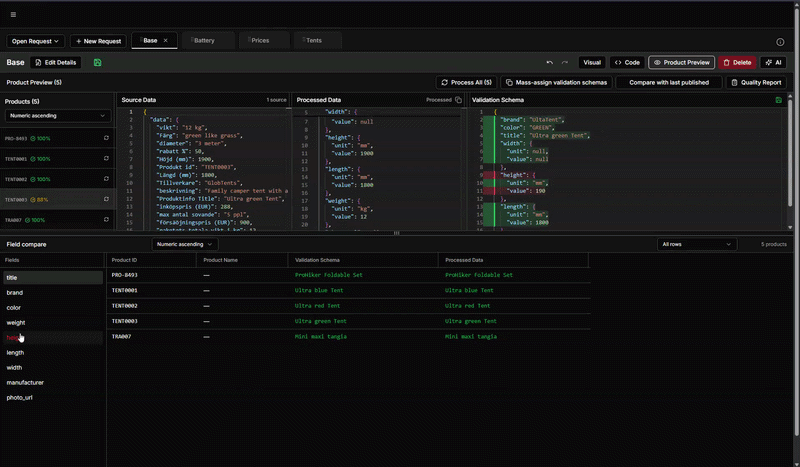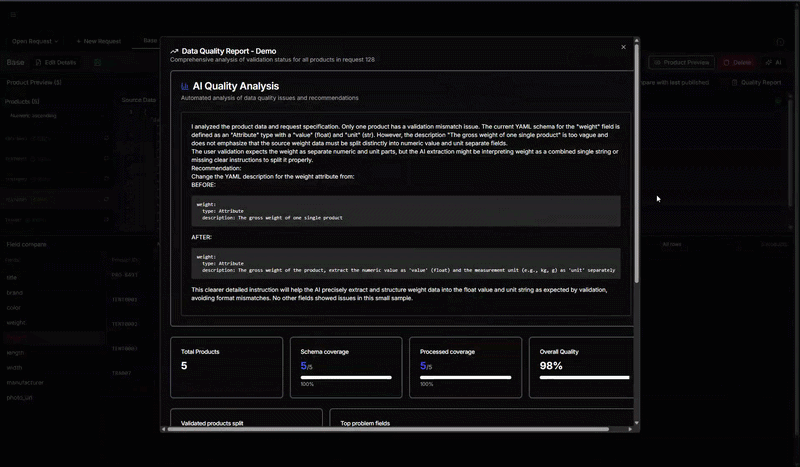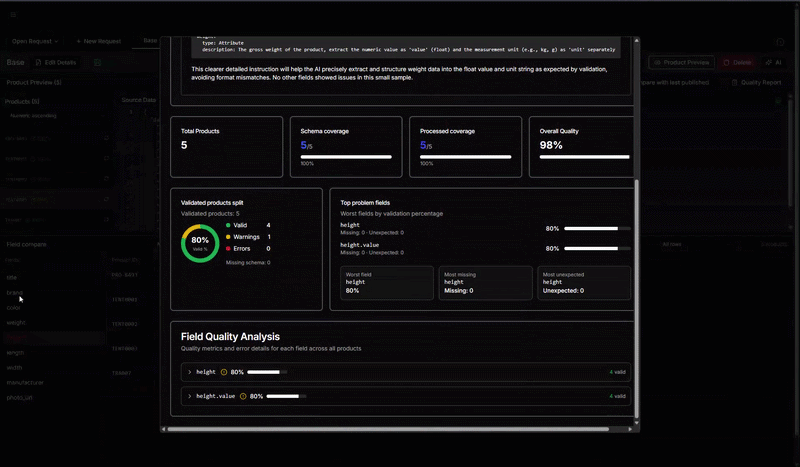
Vi går på djupet i en implementation och visar hur ni tar fram ett testdataset och strukturerar er datamodell och era prompts så att resultatet blir konsekvent. Vi visar också hur ni använder verktygets stödfunktioner för att granska, jämföra och kvalitetssäkra AI-resultat tills ni har en modell ni vågar lita på.
Vi fokuserar på hur man kan styra en AI med hjälp av prompts, olika modeller och hur man utvärderar resultatet.

Talare under detta webinar
Under detta webinar får du ta del av expertis från vår talare Glenn Svanberg, AI Developer & Innovation Advocate på Fiwe. Glenn har lång erfarenhet av att arbeta med AI, datamodeller och implementationer, och delar med sig av insikter från verkliga projekt där Onboarder förändrat arbetet med onboarding av produktdata.
Se detta webinar on demand
Ta del av webinaret där vi visar hur ni bygger en datamodell ni kan lita på – från testdata till stabil AI-extraktion i praktiken. Ta del av webinaret on demand direkt.
Lär dig mer om:
Talare under webinaret:

